Google DeepMind a mis en ligne Gemini 3.5 Flash, une nouvelle version de sa gamme de modèles rapides et accessibles. Ce modèle affiche des gains de performance notables par rapport à son prédécesseur, mais son coût d’utilisation a été multiplié par 5,5 selon une analyse d’Artificial Analysis.
Cette hausse s’inscrit dans une dynamique plus large : Anthropic et OpenAI ont également revu leurs tarifs à la hausse sur leurs dernières générations de modèles.
Une hausse des prix qui dépasse la simple grille tarifaire
Les tarifs officiels ont triplé par rapport à Gemini 3 Flash. Google facture désormais 1,50 dollar par million de tokens en entrée et 9 dollars par million en sortie, contre respectivement 0,50 et 3 dollars auparavant.
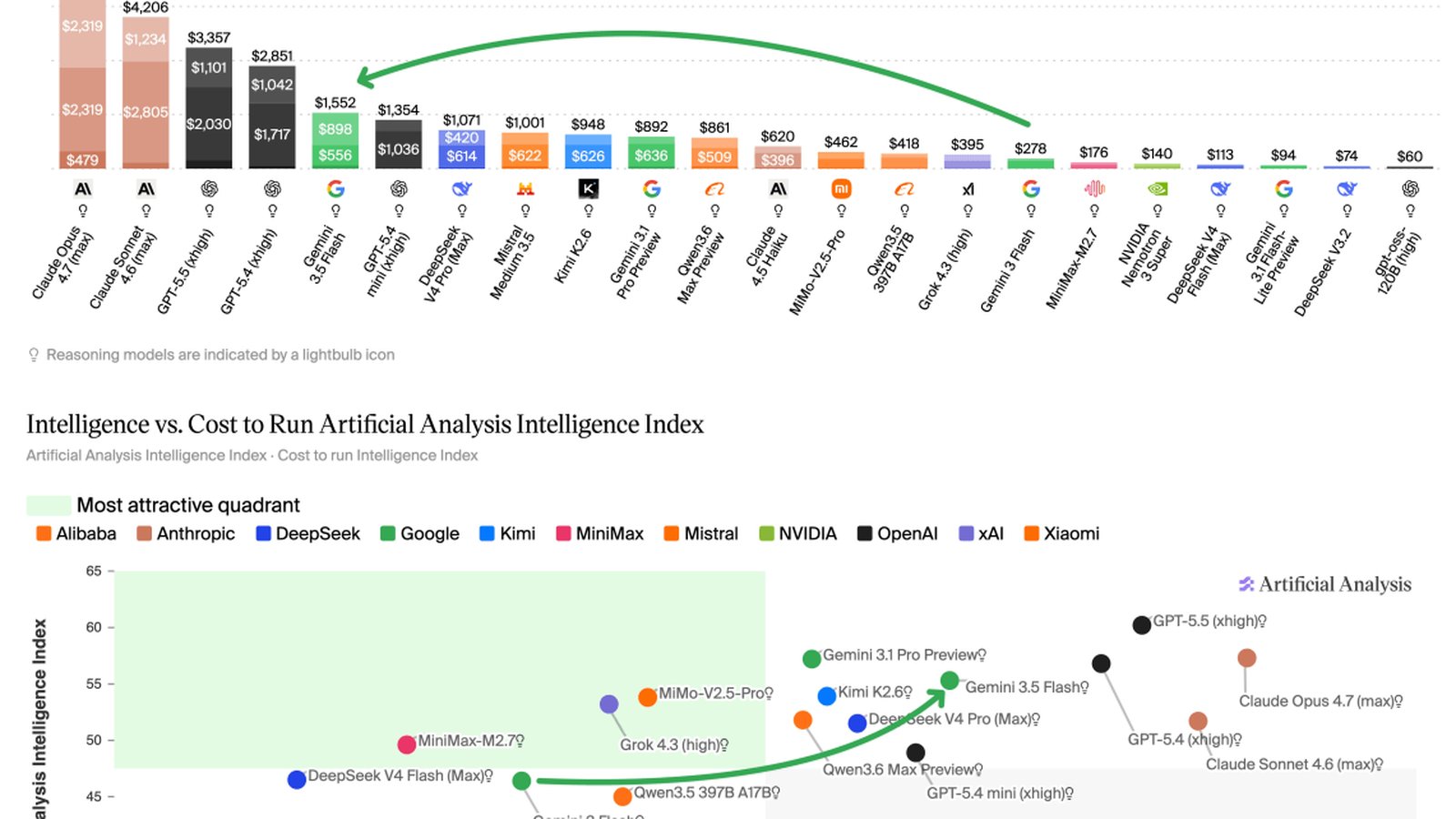
Mais l’impact réel sur les coûts est plus fort encore. Sur les tâches agentiques, Gemini 3.5 Flash consomme en moyenne 49 échanges par tâche, davantage que n’importe quel autre modèle testé. Cette consommation élevée fait grimper la facture totale de 75 % au-dessus de celle de Gemini 3.1 Pro, malgré un tarif unitaire plus bas.
Pour les développeurs, le prix affiché par token devient donc un indicateur insuffisant. Ce qui compte désormais, c’est l’efficacité globale du modèle sur une tâche complète.
Des progrès marqués sur les tâches agentiques et multimodales
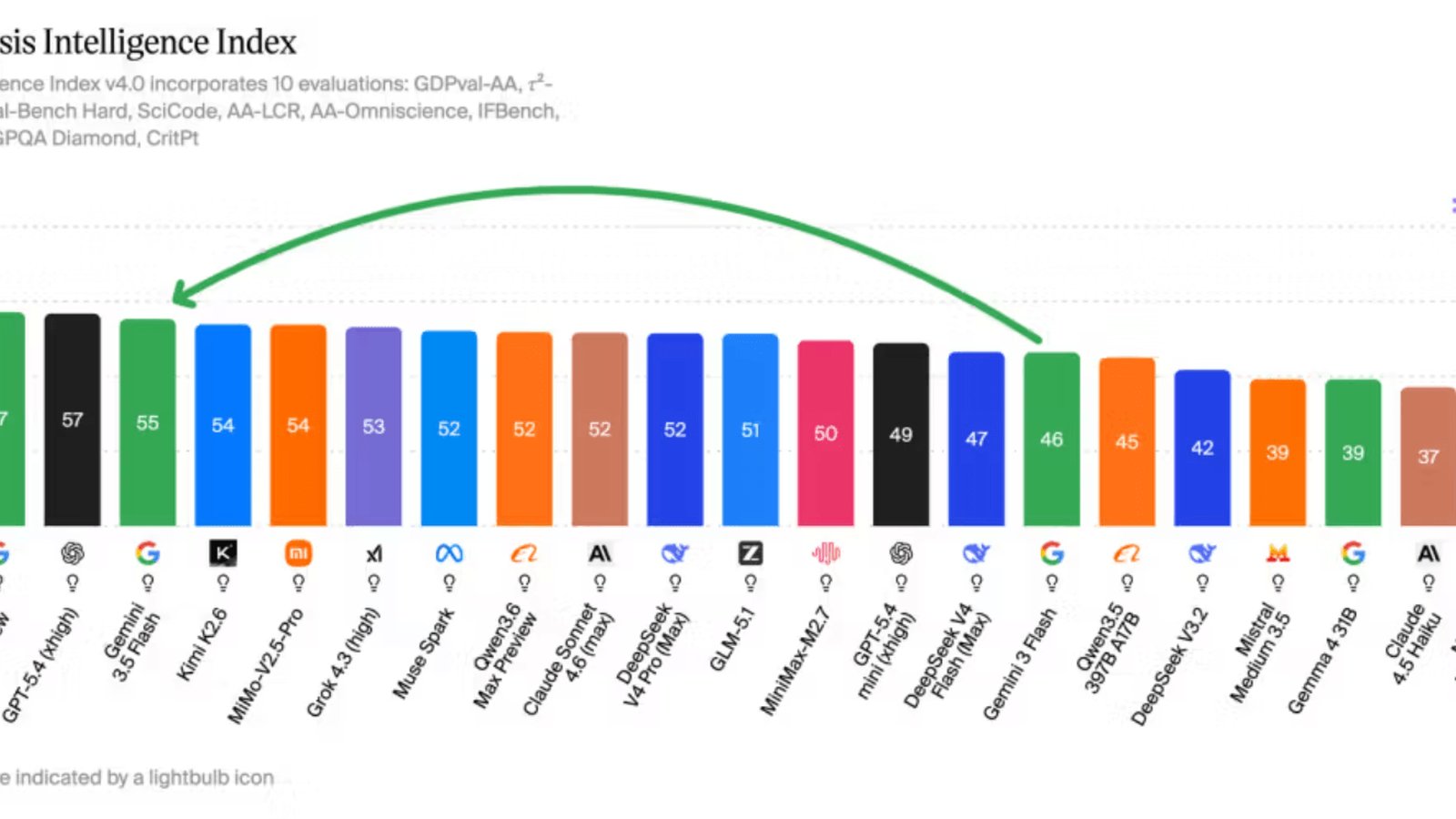
Gemini 3.5 Flash obtient un score de 55 sur l’indice d’intelligence d’Artificial Analysis, neuf points de plus que Gemini 3 Flash. Il dépasse Grok 4.3 et Claude Sonnet 4.6 sur cet indicateur général.
Ses gains les plus nets apparaissent sur les tâches agentiques. Sur le benchmark GDPval-AA, qui simule des tâches réelles avec accès au web et à un terminal, le modèle atteint un score Elo de 1 656, contre 1 204 pour Gemini 3 Flash et 1 314 pour Gemini 3.1 Pro. Il se place juste derrière GPT-5.4 à 1 674.
Sur le plan multimodal, Gemini 3.5 Flash supporte les entrées vidéo et audio, là où des concurrents comme Claude Opus 4.7, Grok 4.3 ou GPT-5.5 se limitent aux images. Sur le benchmark MMMU-Pro, il enregistre 84 %, le meilleur résultat jamais mesuré selon Artificial Analysis.
La programmation reste un point faible
Sur les tâches de code, Gemini 3.5 Flash obtient un score de 45 sur l’indice de programmation d’Artificial Analysis. C’est nettement inférieur à GPT-5.5 (59), GPT-5.4 (57), Claude Opus 4.7 (53) ou Claude Sonnet 4.5 (51). Même Gemini 3.1 Pro Preview (55) fait mieux.
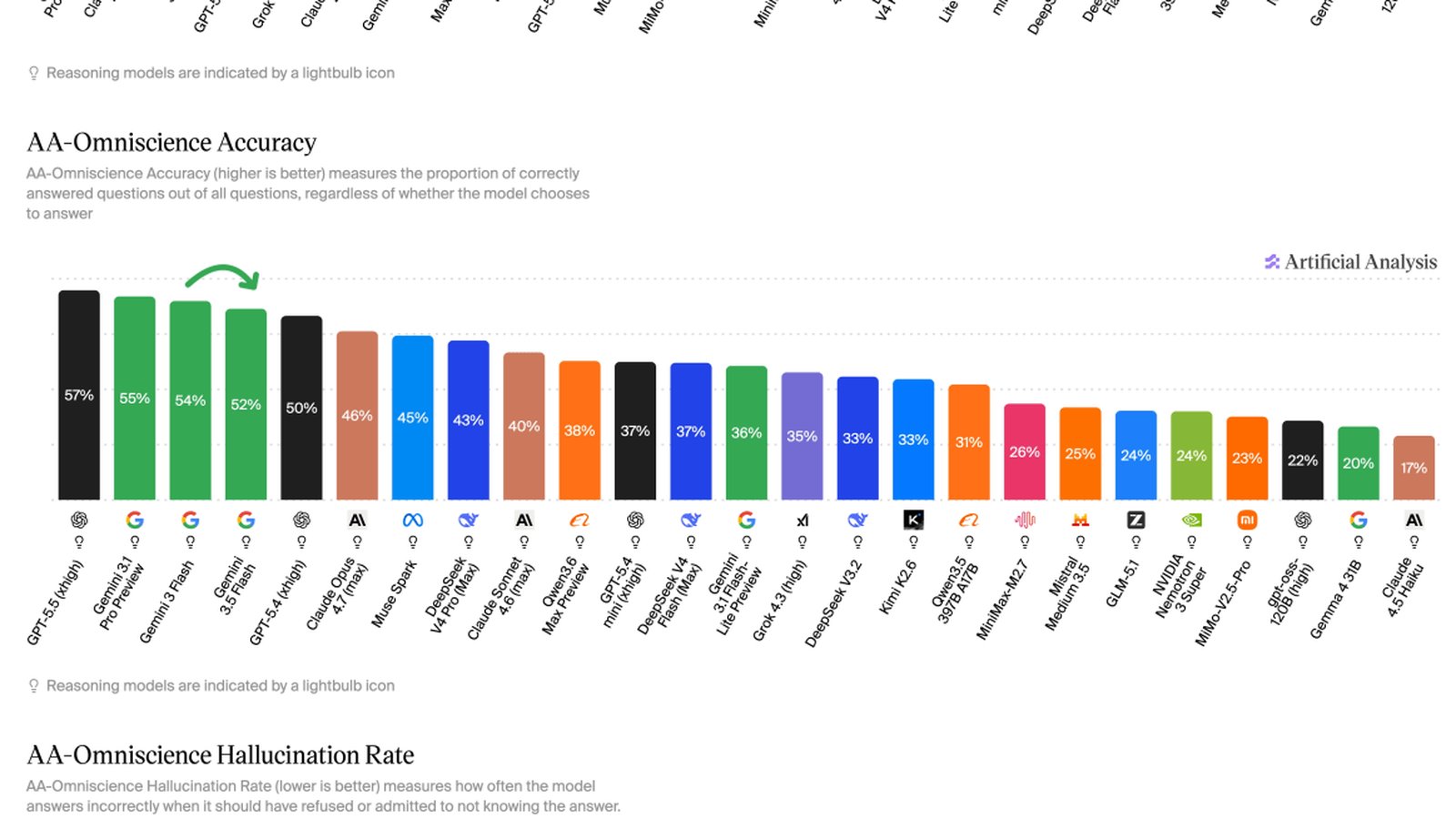
Ce résultat est notable car la génération de code constitue l’un des usages les plus répandus dans les workflows agentiques. Les gains du modèle sur les tâches agentiques en général sont donc partiellement bridés par cette faiblesse spécifique.
La vitesse comme argument différenciant
Gemini 3.5 Flash atteint plus de 280 tokens de sortie par seconde, soit environ 70 % de plus que son prédécesseur. Aucun autre modèle de niveau d’intelligence comparable n’approche ce débit selon Artificial Analysis.
Cette rapidité reste un atout pour les cas d’usage où la latence compte, mais elle ne suffit pas à compenser la hausse des coûts pour toutes les applications. Les modèles plus anciens et moins chers, comme Gemini 3.1 Flash-Lite, restent disponibles pour les tâches simples où la puissance supplémentaire n’est pas nécessaire.
La tendance générale est claire : les nouveaux modèles sont conçus pour des tâches complexes et multi-étapes, ce qui implique davantage de calcul par requête. Tant que les coûts d’inférence matérielle ne baissent pas plus vite que la consommation de tokens n’augmente, les prix continueront de progresser chez l’ensemble des fournisseurs.
Source : The-decoder



